Primal-Dual Hybrid Gradient algorithm¶
The Primal-Dual Hybrid Gradient (PDHG) algorithm was studied in 2011 by Chambolle and Pock in the paper A first-order primal-dual algorithm for convex problems with applications to imaging. It is a method for solving convex non-smooth problems of the form
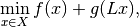
where 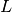 is a linear
is a linear Operator 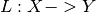 ,
, 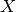 and
and 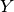 are (discretized) function spaces and
are (discretized) function spaces and ![f : X \to [0, +\infty]](../_images/math/9d6a4ebd8c111e5d4580cedc8a257eefa5cea94e.png) and
and ![g : Y \to [0, +\infty]](../_images/math/d0f8decc0bd208ee5e800e671cb9f70b38b26743.png) are proper, convex, lower semi-continuous functionals.
For more information on the mathematics, please see the mathematical background article on this method.
are proper, convex, lower semi-continuous functionals.
For more information on the mathematics, please see the mathematical background article on this method.
Using PDHG¶
There are several examples in the examples folder of ODL, including denoising, deblurring and tomography. Here, we will walk through the solution of a typical problem using the PDHG solver.
Mathematical problem setup¶
The problem we'll be looking at is the TV regularized denoising problem
![\min_{x \in X} \left[ d(x) + r(x) + \iota_{[0, \infty]}(x) \right]](../_images/math/e7c3cb092031b6d76ce3b2dd48e8750241f0134d.png)
with 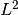 data discrepancy term for given data
data discrepancy term for given data 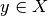 ,
,
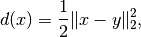
TV regularization term
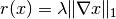
and positivity constraint enforced by the indicator function
![\iota_{[0, \infty]}(x) =
\begin{cases}
0, & \text{ if } x \geq 0 \text{ everywhere}, \\
\infty, & \text{ else }.
\end{cases}](../_images/math/240224f7e1ffcc8cf6afc76f9df63fa09a2a68cc.png)
Here, 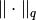 is the
is the 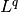 norm (
norm (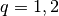 ),
), 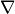 the spatial gradient, and
the spatial gradient, and 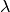 a regularization parameter.
a regularization parameter.
The standard way of fitting this problem into the PDHG framework is to summarize both data fit and regularization terms into the composition part 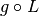 of the solver, and to set
of the solver, and to set 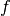 to the positivity constraint
to the positivity constraint ![\iota_{[0, \infty]}](../_images/math/890d3e242ff8baaa858360e65c21c4ebbe062832.png) .
By setting
.
By setting 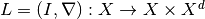 , where
, where 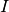 is the identity mapping on , we can write
is the identity mapping on , we can write
](../_images/math/81d3cf24a1003faba11a716af0cf2841028e8744.png)
with the functional 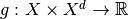 defined by
defined by
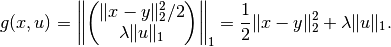
Note that the arguments 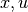 of
of 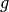 are independent, i.e. the sum of the two functionals is a
are independent, i.e. the sum of the two functionals is a SeparableSum.
Note
The operator maps to the ProductSpace 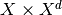 .
Such a "one-to-many" type of mapping is also called
.
Such a "one-to-many" type of mapping is also called BroadcastOperator.
Numerical solution using ODL¶
Now we implement a numerical solution to the above defined problem using PDHG in ODL.
Problem setup¶
The first step in the problem setup is the definition of the spaces in which we want to solve the problem.
In this case, we use an space on the square ![[0, 100] \times [0, 100]](../_images/math/4fdbffff0f3a2ffe7369b71500305efcbd09ba36.png) .
We choose 256 discretization points per axis:
.
We choose 256 discretization points per axis:
>>> space = odl.uniform_discr(min_pt=[0, 0], max_pt=[100, 100], shape=[256, 256])
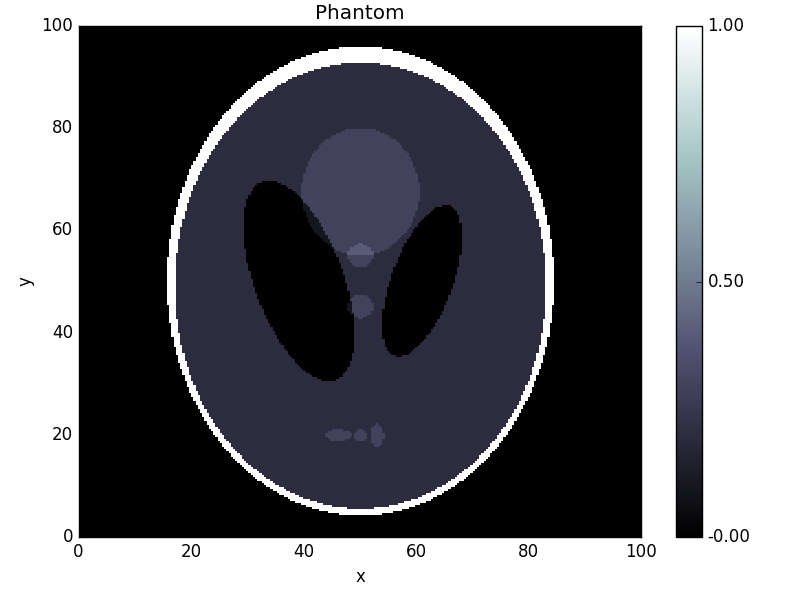
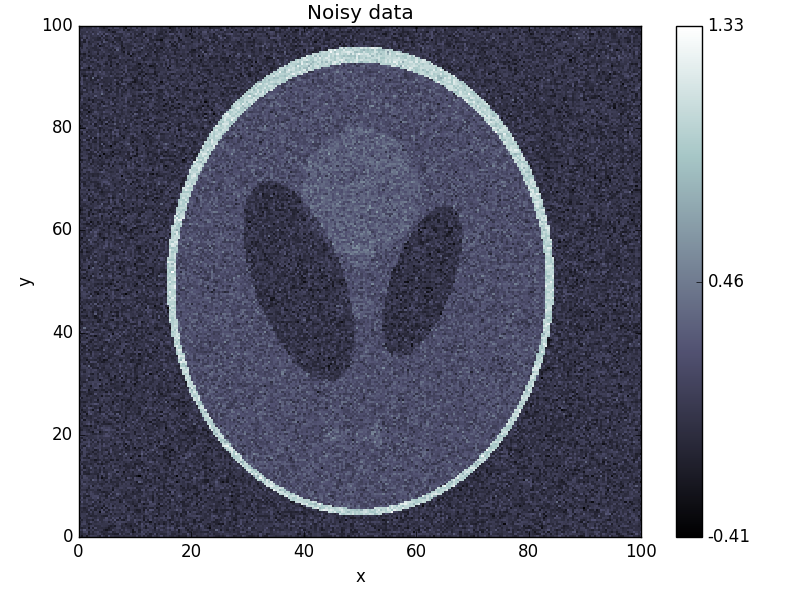
In real problems, the data 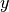 would be given by some measurement, but for the purpose of testing the solver, we generate data by creating a modified Shepp-Logan phantom and adding 10% Gaussian noise:
would be given by some measurement, but for the purpose of testing the solver, we generate data by creating a modified Shepp-Logan phantom and adding 10% Gaussian noise:
>>> phantom = odl.phantom.shepp_logan(space, modified=True)
>>> data = phantom + odl.phantom.white_noise(space) * 0.1
We now need to define the forward operator , which we do one constituent at a time:
>>> ident = odl.IdentityOperator(space)
>>> grad = odl.Gradient(space)
To create , we use the BroadcastOperator class as mentioned above:
>>> L = odl.BroadcastOperator(ident, grad)
We can now proceed to the problem specification.
This step requires us to specify the functionals and , where the latter is the SeparableSum of the squared distance to and the (vectorial) 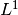 norm.
These functionals are available in ODL as
norm.
These functionals are available in ODL as L2NormSquared and L1Norm, respectively:
>>> l2_norm_squared = odl.solvers.L2NormSquared(space).translated(data)
>>> l1_norm = 0.0003 * odl.solvers.L1Norm(grad.range)
>>> g = odl.solvers.SeparableSum(l2_norm_squared, l1_norm)
Note
We don't need to take extra care of the norm being a vectorial norm since L1Norm also works on product spaces.
Finally, we define the functional for the nonnegativity constraint, available as the functional IndicatorNonnegativity:
>>> f = odl.solvers.IndicatorNonnegativity(space)
Calling the solver¶
Now that the problem is set up, we need to select some optimization parameters.
For PDHG, there is one main rule that we can use:
The product of the primal step 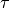 , the dual step
, the dual step 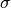 and the squared operator norm
and the squared operator norm 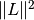 has to be smaller than 1,
has to be smaller than 1, 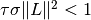 .
Apart from this, there are no clear rules on how to select and -- basically we're left with trial and error.
We decide to pick them both equal to
.
Apart from this, there are no clear rules on how to select and -- basically we're left with trial and error.
We decide to pick them both equal to 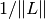 .
To calculate an estimate of the operator norm, we have the tool
.
To calculate an estimate of the operator norm, we have the tool power_method_opnorm which performs the simple power iteration to approximate the largest singular value of :
>>> op_norm = 1.1 * odl.power_method_opnorm(L, maxiter=4, xstart=phantom)
>>> tau = sigma = 1.0 / op_norm
Finally, we pick a starting point (zero) and run the algorithm:
>>> x = space.zero()
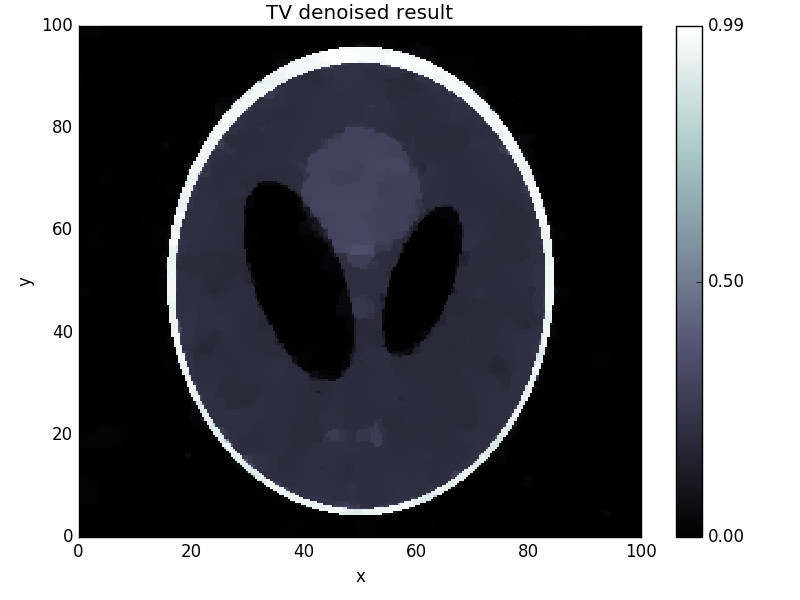
>>> odl.solvers.pdhg(x, f, g, L, tau=tau, sigma=sigma, niter=100)
Now we check the result after 100 iterations and compare it to the original:
>>> fig1 = phantom.show('phantom')
>>> fig2 = data.show('noisy data')
>>> fig3 = x.show('TV denoised result')
This yields the following images: